De nos jours, les logiciels de sauvegarde sont confrontés à des volumes de données de plus en plus importants. Afin d’optimiser les processus de sauvegarde, différentes stratégies ont été imaginées au fil des années. Nous allons les présenter rapidement, avant vous présenter la sauvegarde avec les mécanismes deContent Defined Chunking.
L’état des lieux des évolutions des mécanismes de sauvegarde de données
La Sauvegarde incrémentielle
La sauvegarde dite « incrémentielle » consiste à ne sauvegarder que les fichiers qui ont changé depuis la dernière sauvegarde.
Ce mécanisme de sauvegarde permet de ne pas avoir à sauvegarde l’entièreté des données à chaque sauvegarde. Toutefois, l’inconvénient est évidemment que lors du moindre changement d’un fichier, celui-ci doit être intégralement re-sauvegardé.
La Sauvegarde en mode « bloc »
La sauvegarde en mode « bloc » consiste à ne sauvegarder que les blocs de données qui ont changé depuis la dernière sauvegarde : un bloc étant une morceau (de taille fixe ou variable) d’un fichier, par exemple en décomposant un fichier en des blocs équivalent de 1 Mo.
Ce mécanisme fonctionne bien et permet une véritable optimisation de la bande passante par rapport à la sauvegardeincrémentielle, si les parties modifiées du fichier se trouvent sur seulement quelques blocs. Mais si on ajoute un octet au début du fichier, alors tous les blocs seront modifiés et on revient à de la sauvegarde incrémentielle.
La Sauvegarde avec déduplication à la cible
La sauvegarde avec déduplication à la cible (en post-process) supprime les données redondantes après leur écriture sur le stockage de sauvegarde, les données dupliquées sont supprimées et remplacées par un pointeur vers la première itération du bloc.
Elle permet d’optimiser l’espace de sauvegarde, mais n’optimise pas le nombre de blocs à sauvegarder et donc la consommation de bande passante.
La Sauvegarde avec déduplication à la source
La déduplication à la source qui évite l’écriture de blocs de sauvegarde en double depuis le serveur à sauvegarder et les remplace par un pointeur vers leur première version dans le même ensemble de sauvegarde.
Cette méthode de sauvegarde est basée sur des méthodes de hachage de fichiers.
La Sauvegarde avec « Content Defined Chunking »
Puis vient enfin la sauvegarde avec des mécanismes de déduplication de type « Content Defined Chunking ».
Cette sauvegarde utilise des mécanismes de blocs variables et se basent sur du « hachage roulant ». Elle permet ainsi de reconnaître à nouveau les mêmes morceaux lorsqu’ils sont déplacés ou légèrement modifiés.
Quels sont les besoins couverts par ces mécanismes dedéduplication ?
Les besoins de déduplication dans le domaine de la sauvegarde de données
Les besoins de déduplication sont multiples, en voici quelques exemples :
- Besoin de gain en consommation de bande passante dans un contexte de sauvegarde externalisée (sauvegarde des données sur un Cloud par exemple)
- Besoin de gain en volumétrie cible des espaces de sauvegarde dans des contextes de grandes infrastructures
- Réduction des fenêtres de sauvegarde liées à l’augmentation des volumes à sauvegarder
Selon des études recherches de déduplication réalisées par Microsoft (Meyer et Bolosky, 2012 , El-Shimi et al., 2012 ), et EMC ( Wallace et al., 2012 , Shilane et al., 2012 ), plus de 50% jusqu’à 85% des données seraient redondantes dans une infrastructure conséquente et pourraient être dédupliquées.
En revanche, les impacts de ces solutions de déduplication à la source peuvent être conséquents :
- Consommation de ressources systèmes importante (CPU/RAM/IO) sur les serveurs « source »
- Augmentation de la taille du catalogue de sauvegarde qui peut voir ses performances se dégrader
- Importance des contrôles d’intégrité des mécanismes de déduplication et du catalogue
Comment peuvent-être contournées les limites de la déduplication avec les mécanismes de« Hachage Roulant»
Les limites sur la déduplication basée sur des blocs de taille fixe ou variable ont été contournées avec les mécanismes de Content Defined Chunking.
Terme que l’on pourrait traduire littéralement par « Fragmentation optimisée d’un contenu ».
L’idée générale est de savoir :
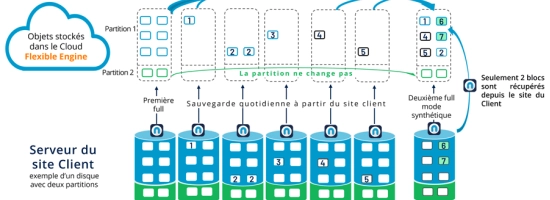
- Découper initialement les fichiers à sauvegarder dans des morceaux de taille variable et en définir une empreinte à stocker dans un référentiel
- Analyser, lors d’une nouvelle sauvegarde, le contenu d’un fichier et de trouver des « motifs » dans le fichier qui sont déjà sauvegardés.
Note : un « motif » est un schéma de données qui se répète, un bloc de petite taille (par exemple de taille de 1 Mo).
Pour ce faire, les sauvegardes de données avec « Content Defined Chunking » utilisent alors des mécanismes de « Hachage Roulant » (ou glissant) qui permet d’essayer de trouver ces motifs en glissant dans le fichier.
Le hachage roulant est une fonction de hachage où l’entrée (par exemple un fichier) est hachée dans une fenêtre (de plusieurs octets) qui se déplace à travers l’entrée (le fichier) pour trouver des blocs de données qui sont déjà sauvegardés (les motifs).
Toute l’intelligence (et l’optimisation) de ces algorithmes consiste à utiliser le moins de ressources techniques (CPU/RAM/IO) pour trouver ces blocs de données.
Historiquement, les premières implémentations de Content Defined Chunking ont utilisé l’algorithme de Rabin-Karp (1987) et ont été optimisées par de nombreux travaux de R&D (empreinte de Rabin, fastCDP, …).
Nous vous conseillons d’explorer les ressources ci-dessus citées si le sujet vous intéresse en profondeur.
Restic : la solution de sauvegarde de données qui utilise le Content Defined Chunking et le Hachage Roulant
Restic est une solution de sauvegarde utilisant les deux mécanismes présentés dans cet article. Nous vous proposons un article approfondissant le sujet de cette solution de sauvegarde.