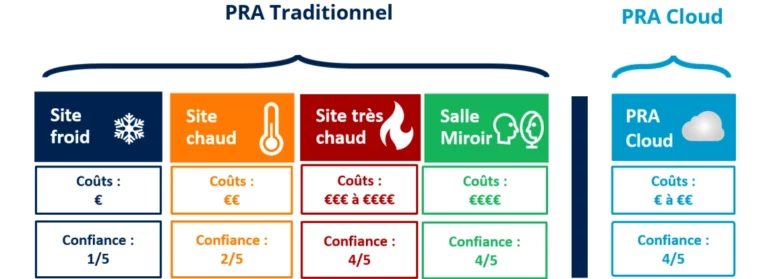
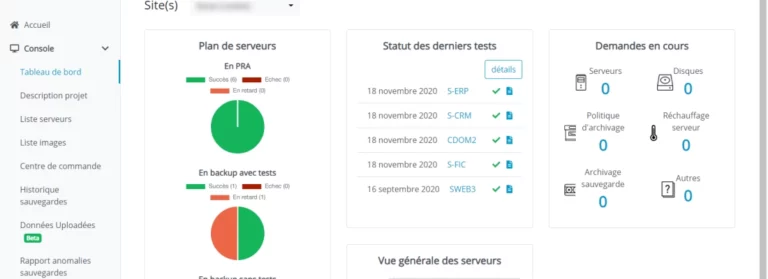
Faire le pas vers le Cloud public n’est absolument pas trivial. C’est un changement de paradigme dans sa gestion par rapport à une infrastructure in-situ et plusieurs points sont à attentivement vérifier afin d’éviter les mauvaises surprises lors de la « cloudification » du SI.
Faire le pas vers le Cloud public n’est absolument pas trivial. C’est un changement de paradigme dans sa gestion par rapport à une infrastructure in-situ et plusieurs points sont à attentivement vérifier afin d’éviter les mauvaises surprises lors de la « cloudification » du SI.
Je vous propose donc de me suivre dans cette série de billets qui parleront des obstacles rencontrés sur la voie vers les « nuages », où je m’exprime en tant qu’OPS qui s’adresse à d’autres personnes disposant un minimum de compétences techniques et qui peuvent être confrontées au besoin de basculer dans le Cloud public, tout ou partie de leur SI.
Préambule
Il est à noter que nous travaillons sur un Cloud basé sur OpenStack, et que les fonctionnalités offertes par les différents Cloud publics différent sensiblement (par exemple entre AWS, Azure et Cloudwatt d’Orange), les différentes expériences relatées ici sont donc à replacer dans ce contexte technique.
Retenez également que le choix du fournisseur de Cloud va grandement influencer votre expérience : la quantité de retours sur AWS sera évidemment plus importante qu’un fournisseur de Cloud public basé sur OpenStack, cependant les recommandations et conseils que je formule ici devraient être suffisamment générales qu’elles devraient s’appliquer à la majorité des Cloud.
Finalement, posez-vous la question de ce que vous allez envoyer dans le Cloud: celui-ci peut vous coûter plus cher que votre infrastructure in-situ si vous ne gérez pas l’extinction et l’allumage des machines aux moments opportuns ou leur augmentation et diminution de consommation de ressources à la volée.
Thèmes abordés
Les sujets abordés dans ces billets vont des points techniquement poussés comme par exemple la préparation d’un système existant aux problématiques générales d’architecture et modèles de licensing dans le Cloud.
« Vaporisation » de vos machines (virtuellees ou physiques) dans OpenStack
Afin de migrer un SI dans le Cloud vous pouvez procéder de deux manières différentes :
- Recréer les systèmes et par la suite migrer les données Migrer en bloc système et données à partir des machines elles-mêmes, en préparant puis transférant leurs disques durs dans le cloud et les lançant depuis celui-ci.
- La seconde option n’est pas triviale : l’idée est de préparer un disque dur amorçable contenant déjà l’OS installé et prêt puis d’envoyer celui-ci dans le Cloud pour l’y faire tourner.
Afin de permettre à un OS déjà existant de démarrer dans le Cloud, il faut veiller qu’il puisse parler à l’hyperviseur du Cloud et dispose des bons drivers avant sa migration. Dans notre cas pour un Cloud se reposant sur la technologie Qemu/KVM, les drivers dont il faut disposer se nomment VirtIO.
Dans le cas d’une machine linux, les drivers pour ce matériel virtuel sont normalement intégrés au noyaux Linux supérieurs à 2.6.25, cependant pour Windows il faut les installer avant l’envoi dans le Cloud. Il faut également à installer une version signée de ces drivers, car les dernières versions de ces drivers disponibles sur le site du Fedora project (lien) ne comportent pas forcement la signature de RedHat.
J’ai écrit un peu plus haut qu’un cloud est un gros hyperviseur abstrait, alors il ne faut pas plus de quatre instructions pour obtenir une instance cloud fonctionnelle :
Arrêter la machine virtuelle à envoyer dans le Cloud par sécurité(Facultatif) Convertir son/ses disque(s) dur virtuel(s) dans un format reconnu par votre Cloud (vmdk, vhd ou qcow2 généralement)Uploader ce disque dur virtuel sur le cloudLancer une instance avec le gabarit approprié sur le réseau désiré !
C’est tout pour cette fois, je m’étendrais plus sur le sujet dans le prochain billet.
Je vous propose donc de me suivre dans cette série de billets qui parleront des obstacles rencontrés sur la voie vers les « nuages », où je m’exprime en tant qu’OPS qui s’adresse à d’autres personnes disposant un minimum de compétences techniques et qui peuvent être confrontées au besoin de basculer dans le Cloud public, tout ou partie de leur SI.
Préambule
Il est à noter que nous travaillons sur un Cloud basé sur OpenStack, et que les fonctionnalités offertes par les différents Cloud publics différent sensiblement (par exemple entre AWS, Azure et Cloudwatt d’Orange), les différentes expériences relatées ici sont donc à replacer dans ce contexte technique.
Retenez également que le choix du fournisseur de Cloud va grandement influencer votre expérience : la quantité de retours sur AWS sera évidemment plus importante qu’un fournisseur de Cloud public basé sur OpenStack, cependant les recommandations et conseils que je formule ici devraient être suffisamment générales qu’elles devraient s’appliquer à la majorité des Cloud.
Finalement, posez-vous la question de ce que vous allez envoyer dans le Cloud: celui-ci peut vous coûter plus cher que votre infrastructure in-situ si vous ne gérez pas l’extinction et l’allumage des machines aux moments opportuns ou leur augmentation et diminution de consommation de ressources à la volée.
Thèmes abordés
Les sujets abordés dans ces billets vont des points techniquement poussés comme par exemple la préparation d’un système existant aux problématiques générales d’architecture et modèles de licensing dans le Cloud.
« Vaporisation » de vos machines (virtuelles ou physiques) dans OpenStack
Afin de migrer un SI dans le Cloud vous pouvez procéder de deux manières différentes :
- Recréer les systèmes et par la suite migrer les données Migrer en bloc système et données à partir des machines elles-mêmes, en préparant puis transférant leurs disques durs dans le cloud et les lançant depuis celui-ci.
- La seconde option n’est pas triviale : l’idée est de préparer un disque dur amorçable contenant déjà l’OS installé et prêt puis d’envoyer celui-ci dans le Cloud pour l’y faire tourner.
Afin de permettre à un OS déjà existant de démarrer dans le Cloud, il faut veiller qu’il puisse parler à l’hyperviseur du Cloud et dispose des bons drivers avant sa migration. Dans notre cas pour un Cloud se reposant sur la technologie Qemu/KVM, les drivers dont il faut disposer se nomment VirtIO.
Dans le cas d’une machine linux, les drivers pour ce matériel virtuel sont normalement intégrés au noyaux Linux supérieurs à 2.6.25, cependant pour Windows il faut les installer avant l’envoi dans le Cloud. Il faut également à installer une version signée de ces drivers, car les dernières versions de ces drivers disponibles sur le site du Fedora project (lien) ne comportent pas forcement la signature de RedHat.
J’ai écrit un peu plus haut qu’un cloud est un gros hyperviseur abstrait, alors il ne faut pas plus de quatre instructions pour obtenir une instance cloud fonctionnelle :
Arrêter la machine virtuelle à envoyer dans le Cloud par sécurité(Facultatif) Convertir son/ses disque(s) dur virtuel(s) dans un format reconnu par votre Cloud (vmdk, vhd ou qcow2 généralement)Uploader ce disque dur virtuel sur le cloudLancer une instance avec le gabarit approprié sur le réseau désiré !
C’est tout pour cette fois, je m’étendrais plus sur le sujet dans le prochain billet.